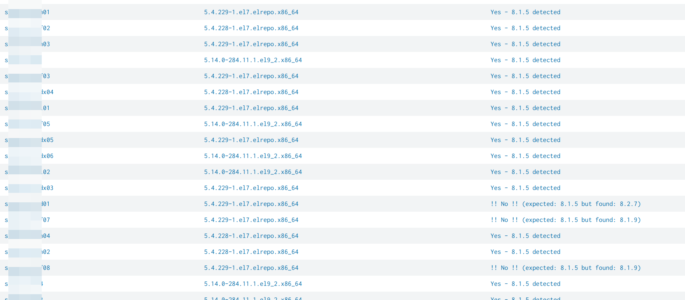
simply query to compare an expected splunk version with reality. simply adjust “expected_version” to your expected version: | rest splunk_server=* /services/server/status/resource-usage/hostwide | table splunk_server splunk_version| eval expected_version=”8.1.5″| eval match_expectation=if(splunk_version == expected_version, “Yes – ” . expected_version . ” detected”, “!! No !! (expected: ” . expected_version . ” but found: ” . splunk_version . “)”)| […]
check expected splunk version with reality